论文速读:MoCoGAN Decomposing Motion and Content for Video
1. Introduction
视频中的视觉信号可以分为内容和运动。内容指定视频中的对象,运动描述它们的动态。在此基础上,本文提出了基于运动和内容分解的生成性对抗网络(MoCoGAN)的视频生成框架。
1.1 Related Work
- 使用循环机制来生成视频片段中帧的运动嵌入(motion)。
- 使用卷积神经网络生成图像(content)。
1.2 Contribution
- 我们提出了一种新的用于无条件视频生成的GAN框架,将噪声向量(noise)映射到视频中。
- 我们展示了所提出的框架提供了一种在视频生成中控制内容和运动的方法,这是现有视频生成框架所缺乏的。
- 为了验证算法的有效性,我们在基准数据集上进行了大量的实验验证,并与目前最先进的视频生成算法VGAN和TGAN进行了定量和主观比较
2. MoCoGAN Framework
MoCoGAN由四个子网络组成,即循环神经网络、图像生成器、图像鉴别器和视频鉴别器
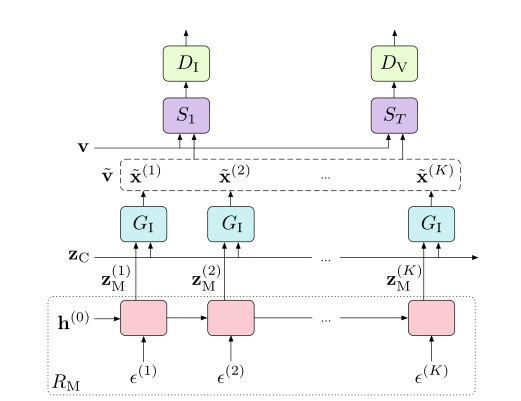
- 使用高斯分布初始化对内容子空间建模,由于在剪辑的短视频中内容基本保持不变,所以我们使用相同的来生成不同帧。
- 视频中的运动由动作子空间建模。用于作为输入的向量序列Z表示

其中 ∈ 以及 ∈ 都各有k个,因为中并不是所有的路径都对应于路径上合理的运动,我们需要学会生成有效的路径,通过循环神经网络对路径生成过程进行建模。
- 即为一个循环神经网络,在每一个时间步k,都会输入一个服从高斯分布的,以及输出一个。假设(k)为时刻k的输出,则 = (k)。本论文中,使用GRU作为的实现。
- 将向量序列Z映射为向量序列,其中 = [, …, ]
- 和分别用于鉴别单个图像和视频序列。获取固定长度的视频片段,例如T帧,T为一个超参数,论文中设为16。T可以小于所生成的视频长度K。长度为K的视频可以以滑动窗口的方式被分成K-T+1个片段,并且每个片段都可以被馈送到中。
- 也用来评估所生成的动作。因为没有运动的概念,因此对于运动的损失将会直接指向循环神经网络。为了骗过,生成具有较为真实动作的视频,必须学会将输入映射为动作系列Z
3. Categorical Dynamics
视频中的动态通常是绝对的(例如,离散的动作类别:行走、跑步、跳跃等)。为了对这个分类信号建模,我们用一个分类随机变量来增加RM的输入,其中每个实现都是一个one-hot向量。我们保持其不变,因为短视频中动作类别保持不变,因此的输入如下图所示。
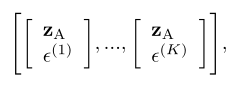
4. Conclusion
以上。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!