论文速读:ImaGINator
1. Introduction
本文提出了一个新的conditional GAN模型,即ImaGINator,在给定单个图像、运动类以及噪声z的条件下,生成视频序列,如下图所示。
原文地址:ImaGINator: Conditional Spatio-Temporal GAN for Video Generation
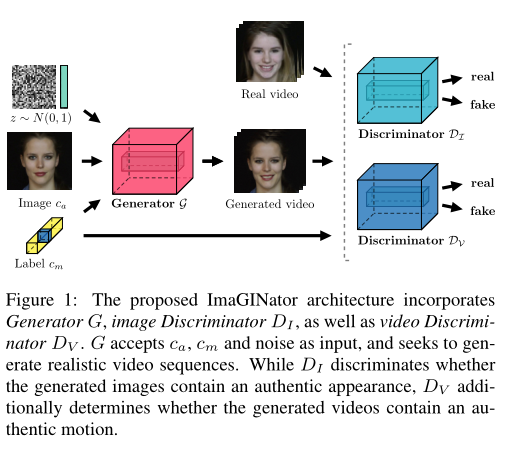
ImaGINator的特性如下:
- 采用了一种新的时空融合机制,旨在通过增强G在低和高特征级别中使用空间信息来保持外观。通过向Decoder注入,我们使G能够将重点放在生成单独的运动上。这是基于这样的假设,即视频可以在潜在空间以及多级时空特征空间中分解成外观和运动。虽然在每一层外观被保留,只有运动被改变。
- 一种新颖的转置(1+2)D卷积,将转置的三维卷积滤波器分解成独立的时间和空间分量。这带来了几个好处:(1)额外的非线性校正允许模型表示更复杂的函数,(2)它便于优化,因为转置(1+2)D卷积块比完全转置的3D卷积滤波器更容易优化,以及(3)它在视频质量和速度方面产生显著的增益
2. Related Work
与之前文章中的MoCoGAN进行比较,MoCoGAN基于seq2seq架构,旨在将时空生成分为两步(将每个视频帧分解为不同潜在空间中的运动和外观)。然而,这种两步生成省略了在更高空间级别的时间一致性的建模,这通常不能保持原始外观。
与此不同,我们提出了一种单步架构,它在多级特征空间中分解运动和外观,用于图像到视频的生成。
3. NetWork Architecture
我们的目标是生成给定外观信息(作为单个图像帧)和运动类别(例如,确定面部表情)的视频序列。我们在这里假设一个视频y可以分解为外观(源自输入图像)和运动(源自类别标签),在此基础上我们继续生成视频。因此,我们将我们的任务表述为学习一个条件映射G: {z,,} → y,其中z ~ N(0,1)表示随机噪声。
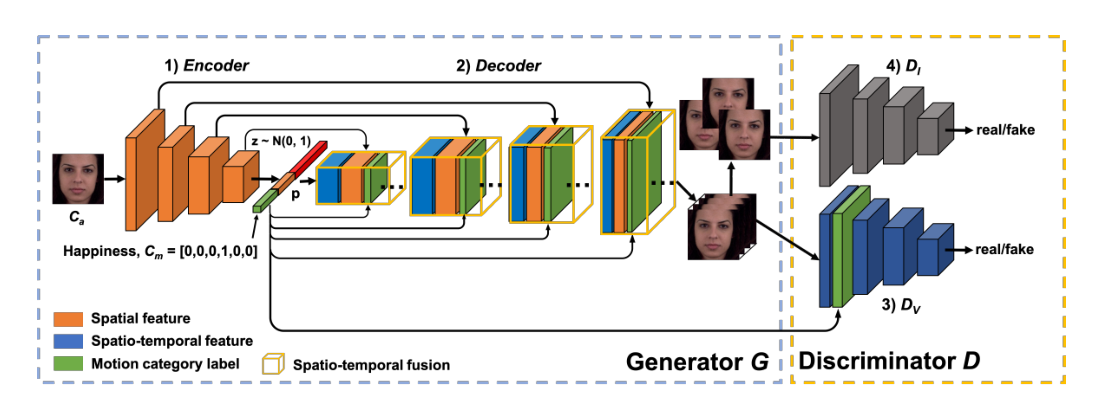
3.1 Generator
我们的Generator由一个图像编码器和一个视频解码器组成,见上图。Encoder提取各种层中的外观信息,从浅的精细层到深的粗糙层。它将输入图像编码为一个潜在矢量p,然后通过连接p、以及随机噪声z ~ N(0,1),Decoder生成一个视频序列。
在我们的生成器B中,我们将使用从2个跳跃连接的FCN-8的想法扩展到4个跳跃连接,但不同之处在于,最初的跳跃连接用于融合预测,而我们的跳跃连接用于融合外观和运动时空特征。我们的跳过连接允许Decoder直接从Encoder访问低级特征,使Decoder能够在每个时间片重用外观特征,并专注于生成运动。
3.1.1 Spatio-temporal fusion.
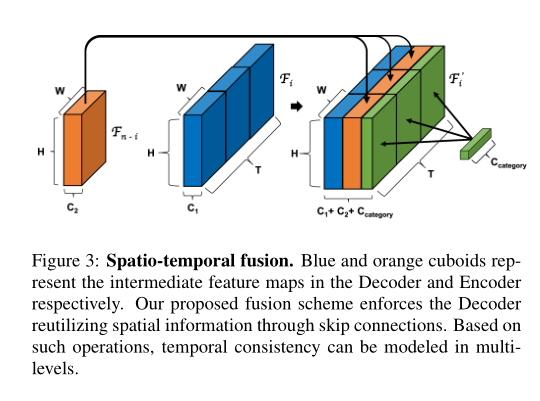
假设G有n个图层,且是G第i层中有个通道的的特征图,,t ∈ {1, …, T}是中第t帧的特征图,是第n-i层的特征图。
如下图所示,我们设计Decoder和Encoder的每一层的输出具有相同的空间维度。我们提出了一种融合机制,在通道方向的维度上连接每个和串联成同一个通道尺寸,得到一个新的特征映射,称为时空融合(Spatio-temporal fusion)。这里我们注意到,每个初始特征映射呈现生成的视频中几个连续帧的时空特征。通过在不同的特征层次上直接时空融合和 ,可以在生成的视频中很好地保留输入信息。
此外,我们将类别标签(构成一个one-hot向量)直接融合到解码器中,以便为每个层提供对标签的访问。为此,我们首先将热点向量投影到热点特征图上。然后,我们在解码器中将类别标签信息时空融合到不同的层中。我们最终的特征地图是大小为H × W × (C1+ C2+)× T
3.1.2 Transposed (1+2)D Convolution
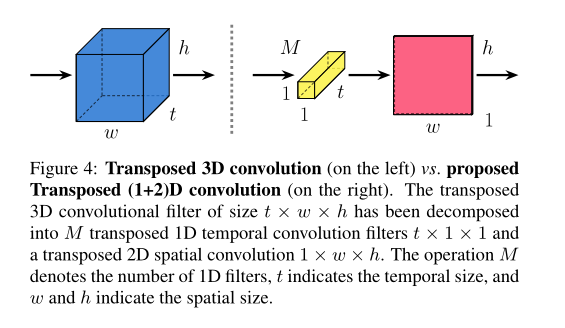
我们注意到,由于难以优化,在一步方法中使用的3D卷积通常会导致产生模糊的视频。然而,得益于空间和时间分解,帧可以在两步方法中单独生成。因此,为了将这种分解结合到一步方法中,我们设计了一个新的卷积层,集成了转置的(1+2)维卷积
我们建议明确地将转置的3D卷积滤波器分解为两个独立且连续的运算,M个转置的1D时间卷积滤波器之后是一个2D独立的空间分量,我们称之为转置的(1+2)D卷积,如下图所示。这种分解带来了几个好处。第一个好处与这两个操作之间的额外非线性校正有关,因此允许模型表示更复杂的函数。第二个潜在的好处是,分解有助于优化,因为具有分解的时间和空间分量的转置(1+2)D卷积块是比完全转置3D卷积滤波器更容易优化。此外,我们表明,分解转置的3D卷积滤波器在视频质量和速度方面都产生了显著的增益。
3.2 Two-stream Discriminator
为了提高视频生成中的图像质量,我们设计了一个包含和的Two-stream Discriminator架构。虽然数字视频有五个3D卷积层,但数字视频只包含具有相同数字视频层数的2D卷积。接受完整生成的视频作为输入,使用建议的时空融合来融合类别标签的“热点特征图”和第一层的输出,类似于G. 试图测量联合分布p(, )和p(, )间的KL散度。我们分别从真实和生成的视频中随机抽取N帧作为输入。
4. Conclunsion
以上。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!