论文速读:G3AN
1. Introduction
原文地址:G3AN: Disentangling Appearance and Motion for Video Generation
在推断和建模人类视频的分布时,生成模型面临三个主要挑战:(a)生成不确定运动,(b)在整个生成的视频中保持人类外观,以及(c)建模时空一致性。
本文提出了一个新的被简化的生成模型,以学习视频生成因子外观和运动的解纠结表示,允许对两者进行操作。解纠缠表示被定义为单个潜在单位对单个生成因素的变化敏感,而对其他因素的变化相对不变[4]。在这种情况下,我们的G3AN被赋予了一个 three-stream生成器架构,其中主流编码时空视频表示,由两个辅助流增强,表示独立的生成因子外观和运动。针对高级功能图的self-attention机制可确保令人满意的视频质量。
因此能够通过遵循训练分布而不需要额外的输入来生成逼真的视频(应对挑战(a)和(c)),并且能够分离地操纵外观和运动,同时强调保持外观(挑战(b))。
本文的技术贡献包括以下内容:
一种新的生成模型G3AN,它试图从人类视频数据中学习生成外观和运动因素的解纠缠表示。这些表示允许对这两个因素进行单独操作。
一种新颖的three-stream生成器,它同时考虑了个体外观特征(空间流)、运动特征(时间流)和平滑生成的视频(主流)的学习
一种新的factorized spatio-temporal self-attention(F-SA)被认为是第一个应用于视频生成的self-attention模块,用于对全局时空表示进行建模,提高生成视频的质量。
广泛的定性和定量评估,证明了G3AN在一系列数据集上系统地、显著地优于最先进的基线。
2. Related Work
虽然视频生成任务旨在生成真实的时间动态,但这些任务会随着条件作用的水平而变化。我们有基于与运动或外观相关的附加先验的视频生成,相反,视频生成仅遵循训练分布。我们注意到,从建模的角度来看,后者更具挑战性,因为缺少关于例如生成的视频的结构的附加输入。因此,迄今为止的大多数方法都包含某种条件作用。
Video generation from noise。从噪声中直接生成视频需要捕获数据集分布并对其建模。最接近本文工作的是MoCoGAN,它将每一帧的潜在表现分解为运动和内容,旨在控制这两个因素。然而,MoCoGAN和之间有两个关键的区别。首先,MoCoGAN不是对每个视频只采样两个噪声矢量,而是采样一系列噪声矢量作为运动,一个固定的噪声作为内容。然而,为每一帧引入随机噪声来表示运动增加了学习难度,因为模型必须将这些噪声向量映射到生成的视频中的连续人体运动。因此,MoCoGAN逐渐忽略输入噪声,并倾向于产生类似的运动。
3.Approach
在这项工作中,我们提出了,一种新颖的GAN架构,旨在从两个噪声矢量 ∈ 和∈ (分别代表外观和运动)中以分离的方式生成视频。由一个三流发生器G和一个双流鉴别器D组成,如下图所示。G的目标是生成能够同时调节外观和运动的视频,而D则分别在视频和帧中区分生成的样本和真实数据。
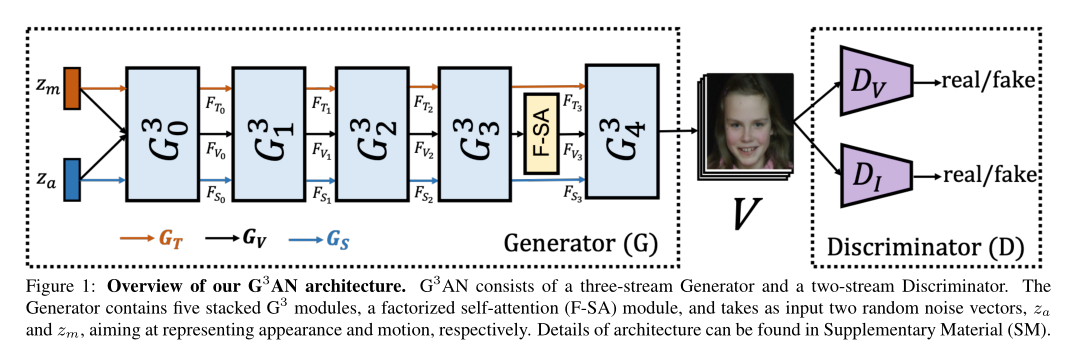
3.1 Generator
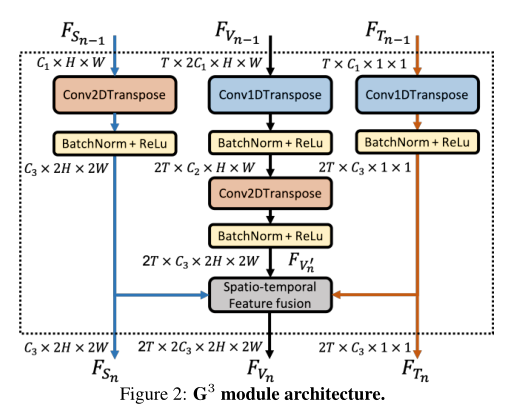
我们在模块的层次结构中设计G。具体来说,我们有N个层次,表示为。第一个模块接受两个噪声矢量和作为输入。其余模块,继承三个特征映射、和,作为它们来自每个先前模块的输入,如上图所示。
每个模块由三个并行流组成:空间流、时间流以及视频流。它们被设计成产生三种不同类型的特征。在上图中用蓝线表示的空间流将n = 0时的和n > 1时的作为输入,并通过使用转置的2D卷积层对输入特征进行上采样来生成2D外观特征。这些特征在空间维度上发展,并在所有时间实例中共享。用橙色线表示的时间流接受n = 0的和n > 1的作为输入,并试图通过用转置的1D卷积层对输入特征进行上采样来生成1D运动特征。这些特征在时间维度上演化,并包含每个时间步长的全局信息。然后,用黑线表示的视频流将n = 0的、和n > 1的的连接作为输入。它对时空一致性进行建模,并通过对输入要素进行上采样和因子化转置时空卷积来产生3D联合嵌入。然后将和弹射到时空融合块,在此与融合,产生。最后,、和作为下一个分层的输入。
王等人在[40]中提出了Factorized transposed spatio-temporal convolution。它明确地将转置的3D卷积分解成两个独立且连续的运算,M个转置的1D时间卷积之后是2D独立的空间卷积,其被称为转置的(1+2)D卷积。这种分解在这两个操作之间带来了额外的非线性激活,并有助于优化。至关重要的是,分解转置的3D卷积产生了视频质量的显著提高
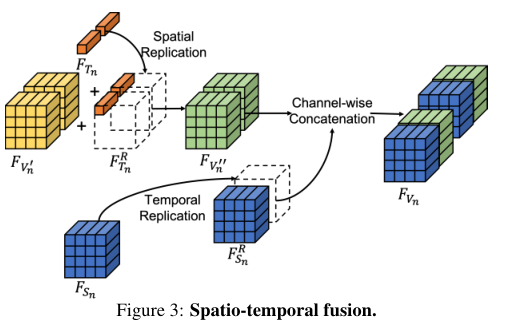
Spatio-temporal fusion是学习好解纠缠特征的关键,其输入是来自每个模块卷积层的输出特征映射、以及。融合包含三个步骤(见下图)。首先,分别对和进行空间和时间复制,以获得两个新的特征图和。两个新的特征图都具有与相同的时空大小。接下来,通过位置相加将和合并,创建新的时空嵌入。最后,将与通道相连接,获得最终的融合特征图。该功能将、和映射为以下模块的输入。
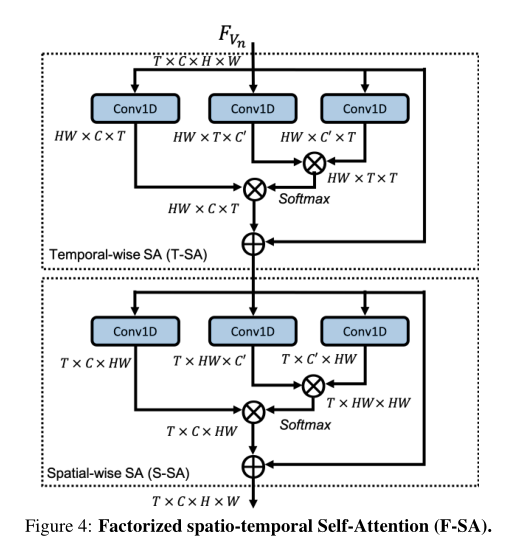
Factorized spatio-temporal Self-Attention (F-SA):在这里,我们结合了一个时空模拟模块,使G能够利用来自所有时空特征位置的线索,并对广泛分离的区域之间的关系进行建模。然而,计算3D时空特征地图中每个位置与所有其他位置之间的相关性在计算上非常昂贵,特别是如果它应用于G中的更高特征地图。因此,我们提出了一种新的因子化时空自我注意,即F-SA,如下图所示。它由一个时间上的模拟退火算法和一个空间上的模拟退火算法组成。这种因子分解减少了计算的复杂性,允许在更大的特征地图上应用因子分析
3.2 Discriminator
为了提高视频和帧质量,类似于MoCoGAN,我们使用了一个双流鉴别器架构,包含一个视频流DV和一个图像流DI。在训练期间,数字视频接受完整的视频作为输入,而双标签从视频中随机抽取帧
4. Conclusion
以上。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!