论文速读:TwoStreamVAN
1. Introduction
原文地址:TwoStreamVAN: Improving Motion Modeling in Video Generation
像素级视频预测[27,36,40]和生成方法的一个主要问题是,它们试图在单个纠缠生成器中对静态内容和动态运动进行建模,而不管它们是否在潜在空间中解开运动和内容\
本文认为在解码阶段分离运动和内容建模是至关重要的。一方面,它消除了内容生成过程中的运动干扰,并产生了更好的内容结构。另一方面,单独的运动建模有助于在整个序列中一致地产生与动作相关的运动。
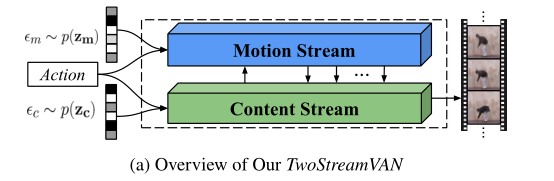
本文提出了一个新的TwoStreamVAN,它从一个动作标签和一个分离的噪声向量生成一个视频,如上x`图所示。通过两个并行的生成器,分别处理内容和运动,并将它们融合在一起以预测下一帧,而不是高估单个生成器的能力(如MoCoGAN的做法)。
直观地说,运动通常以其局部上下文窗口内的空间信息为条件,例如,在做跳跃动作时,手臂和腿部附近的不同运动。因此,我们将运动和内容的融合定义为对每个位置唯一的像素值的学习细化。为了精确地生成多尺度运动,我们在具有几个不同分辨率的中间内容层上进行这种细化。此外,我们还引入了运动蒙版,使运动聚焦于它所在的区域。
本文将引入图像级监控(image-levelsupervision),虽然MoCoGAN尝试了图像级监控缺效果甚微,因为内容生成仍然受到单个共享生成器中运动建模的影响。本文使用的双流生成器的关键优势是能分别学习每个流,从而更准确。我们通过图像级监控完全了解其自身生成器中的图像结构,这显著提高了内容生成性能。训练有素的内容生成进一步有利于视频级监控中的动作学习。
本文贡献如下:
- 我们提出了一个视频生成模型TwoStreamVAN和一个更有效的学习方案,解决了生成阶段的运动和内容问题。
- 我们设计了一种多尺度运动融合机制,并通过对空间环境的调节进一步改进了运动建模
- 我们创建了一个大规模的合成视频生成数据集,供研究团体使用
- 我们在四个视频数据集上通过定量和定性分析评估了我们的模型(通过用户研究),并证明了强于几个强基线的结果。
2. Related Work
本文结合了VAE和GAN,提出了一个变分对抗网络(VAN)来学习一个可解释的潜在空间以及生成现实的图像。鉴于VAN在图像生成方面的成功,我们在此将其用于视频生成。
MoCoGAN试图通过从单独的潜在空间中采样来解开内容和运动,但是使用单个生成器来一起解码这两个潜在代码。为了克服统一生成过程中无效的运动建模和随之而来的内容恶化,我们进一步引入了分离的内容和运动生成器来分别对空间结构和时间动态进行建模。
3. Approach
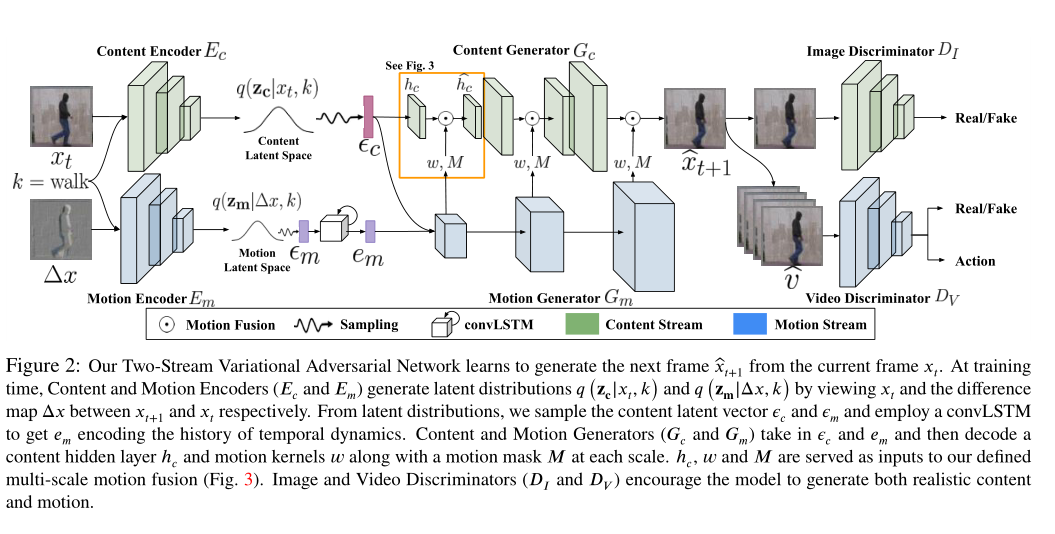
我们引入了一个双流变分对抗网络(图2),它生成一个给定输入动作标签和随机噪声向量的视频。我们定义动作条件视频生成如下。假设我们有K个不同的动作类。在每个类别k ∈ 1: K 的情况下,为该类别训练视频的数量。使 = {}为类别k视频的集合,={}为一个T帧的短视频。任务是定义一个函数G,该函数根据来自潜在向量 ∈ ,给定类别标签k,生成可信的视频,即
我们将潜在空间分解成两个独立的代码:内容代码∈ 和动作代码∈,N = C + M.我们还将视频生成函数G分解为两个独立的内容和运动函数($ G{c} $和$ G{m} $),与以前使用单个生成器的工作形成对比,我们设计了一种新的多尺度融合机制。
3.1 Two-Stream Generation
为了学习内容和运动建模的生成函数$ G{c} $和$ G{m} $,我们引入了两个独立的、在几个阶段具有交互作用的以动作为条件的VAN streams。每个steam包含一个Encoder,一个Generator和一个Discriminator,其中Encoder和Generator作为VAE的自动编码器,Generator和Discriminator组成了GAN
Content VAN Stream由内容编码器$ E{c} $、内容生成器$ G{c} $和图像鉴别器$ D{I} $组成,在观察了x之后,生成了后验内容潜在分布$ q(z{c}|x,k) $,这接近于它的真实先验分布$ p(z{c}|k) $.$ G{c} $将采样自内容分布的的内容向量$ \epsilon{c} $解码成帧。$ D{I} $鉴别帧的真假以鼓励$ G_{c} $生成更真实的图像。
类似地,Motion VAN Stream由运动编码器$ E{m} $、运动生成器$ G{m} $和视频鉴别器$ D{V} $组成,在我们的方法中,$ E{m} $不是对空间内容进行编码,而是对相邻帧之间的差异图$ \triangle x $的时间动态进行编码。它产生的后验运动潜在分布$ q(z{m}|\triangle x,k) $接近其真实的先验分布$ p(z{m}|k) $.convLSTM对运动历史进行累积,并生成当前运动,嵌入$ e{m} $,从所有先前时间步长的运动分布中接收$ \epsilon{m} $序列。$ G{m} $通过$ \epsilon{c} $和$ e{m} $在不同的尺度上产生运动。我们通过将生成的运动与T时间步长的相应内容融合来生成每个视频$ \hat{v} $。$ D{V} $对真实/生成的视频进行了分类,并对他们的行为进行了分类,以鼓励$ G{m} $生成逼真的动作
Multi-scale Motion Generation and Fusion
在像素(a, b)处,运动通常发生在相邻帧之间的局部窗口内。受帧插值空间卷积的启发,我们将运动表示为当前像素值基础局部上下文的细化,并通过空间自适应卷积将这种运动与内容融合。此外,我们提出了一种新的多尺度融合机制来克服其方法的缺点,即:1)由于在全分辨率图像上执行单个融合步骤而导致的多尺度运动的无效建模,以及2)由于用于表示最大可能运动的大卷积核而导致的对存储器的高需求。
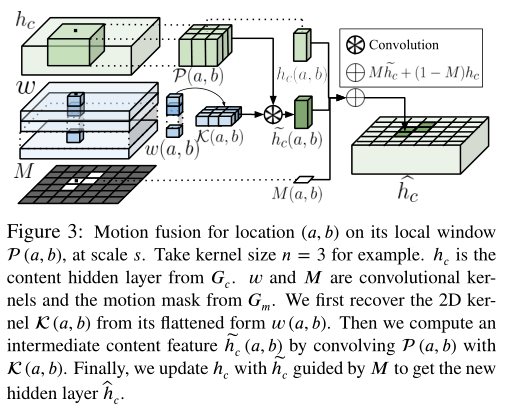
为了生成精确的运动,$ G{m} $将解开的内容和运动嵌入($ \epsilon{c} $和$ e{m} $)作为输入。在$ G{m} $中,不同尺度的运动将相应的隐藏层分开:大的运动来自低分辨率层,小的运动来自高分辨率层。在每一层,$ G_{m} $将当前特征映射为:1)以具有尺寸n的像素方式的2D核的形式计算运动(像素细化);2)识别运动遮罩中包含实际运动的区域;3)生成下一层的运动图。为了将运动与内容融合,仅当像素位于运动被激活的区域中时,我们才分别将生成的2D核与以相应像素为中心的面片进行卷积(即,执行空间自适应卷积)(参见上图)。
具体来说,假设我们把运动分成S个尺度。对于每个尺度的s,让$ l{s} $为相对应的分辨率隐藏层,$ w^{s} ∈ ℝ^{l{s}×l{s}×n^{2}} $为$ G{m} $产生的卷积核,$ h{c}^{s} ∈ ℝ^{l{s} × l{s} × d{s}} $为相对应的内容层,其中$ d{s} $是内容特征维度。我们在以下步骤中执行空间自适应卷积。首先,对于每个位置(a,b),我们从展开形式$ w^{s}(a,b) $恢复一个2D卷积核$ K^{s}(a,b) $.然后,我们将$ K^{s}(a,b) $与在$ h{c}^{s} $的补丁$ P^{s}(a,b) ∈ ℝ^{n×n×d{s}} $做卷积运算来生成一个位置(a,b)中间内容表示 $ \tilde{h}{c}^{s}(a,b) $:
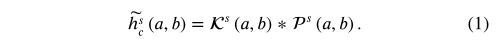
我们通过向较小的层添加自适应卷积来处理较大的运动,而[29]则通过增加核大小来处理较大的运动。由于要存储和建模的参数数量在核大小中是平方的,因此在我们的多尺度融合框架中,我们通过对所有层利用小核(푛=3或5)来显著降低内存使用量和模型复杂度
为了$ G{m} $的注意力集中学习尺度s在实际发生的区域的运动上,我们预测了一个带有$ w^{s} $的运动遮罩$ M^{s} ∈ ℝ^{l{s}×l{s}} $,以识别这样的区域。每个$ M^{s} $的的值都在[0,1]中。我们在$ M^{s}(a,b) $:的指导下通过融合运动从$ h{c}^{s}(a,b) $和 $ \tilde{h}{c}^{s}(a,b) $生成了新的内容$ \hat{h}{c}^{s} $:
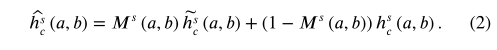
Conclusion
以上。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!